
StartApp is a mobile media and data company that leverages its rich insights into mobile users’ intents and behaviors to power innovative mobile-driven solutions that help partners optimize and better execute their business strategies. StartApp partners with over 500,000 applications, reaching over 1 billion MAUs worldwide. Founded in 2010, the company is headquartered in New York with offices around the world.
StartApp, a pioneer in understanding the intents, behavior, and preferences of mobile consumers, analyzes hundreds of unique data signals from its global database of over 1 billion mobile users to deliver custom, innovative, and mobile-driven audiences and solutions to its partners. StartApp’s SDK, which allows app developers to add a revenue source from in-app advertising, was widely available in early 2011 after the founding of the company. By 2015, over 200,000 apps were using the SDK. Now, that number has grown to over 500,000.
“We are incredibly proud to have reached this milestone” said Gil Dudkiewicz, CEO and Co- Founder of StartApp. “We’ve been expanding and refining our SDK for over 8 years now and are lucky to have such an engaged and growing developer community. We look forward to continuing to provide app developers with the tools and solutions they need to build their app businesses.”
The challenge: migrating big data analytics to the cloud
The news of StartApp’s 500,000th app closely follows the release of the Kochava Traffic Index by Kochava, a leading mobile attribution and analytics platform. In the report, which looked at signal clarity, fraud, traffic quality, and click-to- install correlation, StartApp was ranked as the #6 overall media partner. StartApp’s ability to provide value to its customers depends heavily on its ability to store huge amounts of user data, analyze the data rapidly, and provide relevant responses, all within milliseconds.
StartApp utilizes an on-premise installation of Vertica to store the company’s big data. The data about user behavior and other metrics weighs approximately ½ petabyte, based on 4- month data retention. However, StartApp product manager sometimes needed to zoom on specific metrics up to 12 months back in time. Since these research queries were rarely used, it wasn’t cost-effective to triple the size of the database allowing a one-year data retention. This is why Twingo’s architects suggested to adopt a data lifecycle management approach.
Optimizing cost-efficiency with data lifecycle management
Data Lifecycle Management (DLM) is a policy- based approach to managing the flow of an information system’s data throughout its lifecycle – from creation and initial storage, to the time it becomes obsolete and is deleted, or is forced to be deleted through legislation. The data was categorized into two types: the real- time operational data – which kept all the parameters with a 4-month data retention and the research data – which consisted only on research-relevant parameters with a 12-month data retentions.
Since Vertica is billed by data volume, Twingo experts advised it would be more cost-effective to store the research data on Amazon S3 queried by Amazon Athena, which is billed according to the amount of data scanned in each query. Additionally, Amazon S3 and Athena are PaaS and SaaS respectively, which are significantly cheaper due to minimal IT maintenance.
Minimizing the data scanned in each query
To improve cost-efficiency even more, Twingo experts suggested minimizing the volume of the scanned date using two tactics: on the row-side, and on the column-side. The entire data was divided into daily partitions, which meant that upon query, only partitions representing the requested period were scanned, minimizing the number of rows scanned.
The second tactic was converting the data into Parquet files and saving them in Amazon S3. Parquet is a column-based template, where the data is compressed even more. This meant that upon query only the files representing the relevant table columns were scanned and the therefore the number of columns scanned was also minimized.
Adding the weekly batch processes
StartApp facilitates the exposure of application users to profile-targeted adds. Naturally, the process of directing each user to the right advertisement based on numerous parameters, had to be conducted in the real-time, based on large quantities of data. However, determining the user’s profile was a weekly offline process, the characterized each user by his or her behavioral patterns. In the second project it was decided to perform these offline batch processes on Amazon rather than the operational on-prem Vertica database, in order to avoid performance degradation of the real- time processes due to the offline process.
Offloading the batch processes to Amazon S3 meant that the data had to be split between the on-prem Vertica DB and the Amazon S3 DB right away, unlike the previous architecture where ETL processes were replicating data from Vertica to S3.
Making the right decisions along the cloud migration
Along the project, Twingo cloud experts encouraged StartApp to migrate to the cloud, helping the company making some critical choices along the way. The first dilemma was choosing between Google Big Query and Amazon, but it turned out that not only Amazon had better querying capabilities, but also it turned out to be cheaper than Google.
Additionally uploading methods (from the on- prem environment to the cloud) had to be addressed. StartApp preferred Filesystem in User-space, which didn’t meet the expectations. Filesystem in User-space (FUSE) is a software interface for Unix-like computer operating systems that lets non-privileged users create their own file systems without editing kernel code. This is achieved by running file system code in user space while the FUSE module provides only a “bridge” to the actual kernel interfaces. Twingo recommended to use Amazon Command Line Interface (CLI), which turned out to be successful and easy to configure.
Addressing privacy concerns
The data stored by StartApp is personally identifiable information, since every record is related to the advertising ID. An advertising ID is a user resettable ID assigned by the device or operating environment to help advertising services. It can be sent to advertisers and other
third parties which could be used to track the user’s movement and usage of applications. In the on-prem Vertica database Twingo used a cryptographic hash function to hide the advertising ID. A cryptographic hash function is a special class of hash function that has certain properties which make it suitable for use in cryptography. It is a mathematical algorithm that maps data of arbitrary size to a bit string of a fixed size (a hash) and is designed to be a one- way function, that is, a function which is infeasible to invert.
However, to avoid saving PII in Amazon it was decided that only the user ID will be saved in Amazon. The user ID is an internal StartApp user unique identifier mapped to each advertising ID, but the conversion table isn’t stored in Amazon. Nevertheless, the architecture needed to take into accounts the users’ right be forgotten, so when a the advertising ID is deleted from the conversion table due to a user request, a periodic process rewrites the aggregated files so that the records associated with the relevant user ID are deleted. Additionally, Twingo ensured that the data stored in S3 will be encrypted.
Architecture of Solution 1
Implementing data lifecycle management using hybrid on-prem/cloud solution
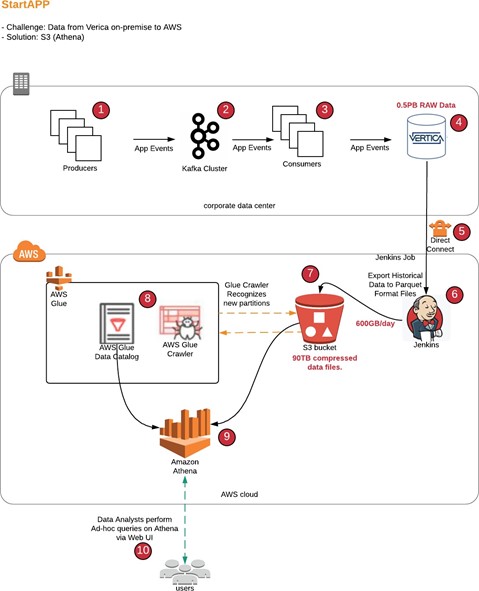
The solution architecture is composed of the following processed and components:
- Producers (1) send app events and other data entities to Kafka Cluster (2) while consumers (3) consume the data from Kafka, and the data is ingested to Vertica (4) cluster;
- Periodic task is running on daily basis in Jenkins (6), the task extracts the 1 day of old data (3 month old) from Vertica to files in parquet format using built-in functionality in Vertica (‘export to parquet’) to on-premise NFS storage, and then AWS libraries are used to upload the files to S3 bucket (7) via AWS direct connect;
- The bucket structure where the files are kept is defined as a table in Glue catalog, with daily partitions;
- Periodical Glue job (8) is triggered to discover the new partitions in S3 and to add them to Glue catalog, so the partitions become visible in AWS Athena (9);
- As a result all data needed for historical queries exists in S3;
- Analysts (10) are querying the data accessing Athena via AWS Console web.
Architecture of Solution 2
Streaming fresh event data to AWS S3 and moving machine learning from on-prem to AWS
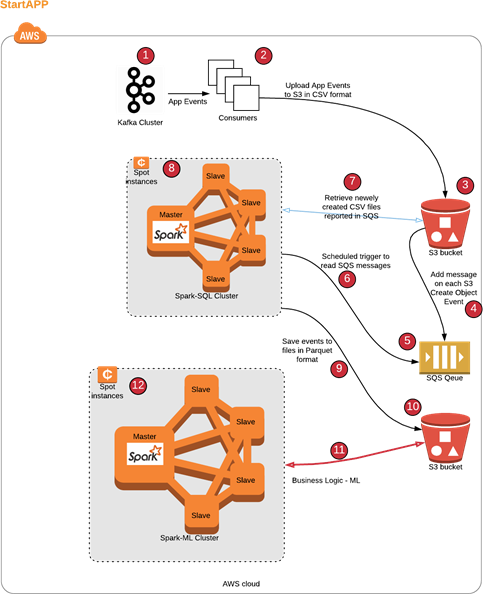
The solution architecture is composed of the following processed and components:
- The raw events from Kafka (1) are pulled with proprietary consumers (2) (Running on EC2) to S3 bucket (3) in CSV format (this is same code which runs on premise adopted for S3);
- The events are coming in the volume of 600GB per day;
- Each new file in S3 bucket publishes event message(4) to AWS SQS (5);
- Periodical job “CSV TO PARQUET” (6) wakes up, retrieves new files using names in AWS SQS (5), then transforms the files to partitioned parquet files using Spark (8) (on Spotinst) and writes the result to another S3 bucket (10); TODO: Are there any data transformations?
- Now we have recent app events data on S3 in addition to the on-prem Vertica;
- Periodical job runs main model (Spark on spotinst) against the event data in S3, additional more complex models were applied since Spark is more flexible than Vertica.
A well-architected design
As part of the solution design, Twingo’s cloud architects addressed relevant aspects:
Operational – The whole process was designed to run in a fully automatic way. The process performs complementary calculations and retrieves missing data in case of one-time gaps that can occur because of missed Jenkins job execution or connection outage between AWS and the on-premise environment.
Reliability – Regarding connectivity, it’s been advised to the customer to establish additional connection from the on-premise environment to AWS. Additional connection type would be an AWS site-to-site IPSec connection over the internet. Since the Jenkins retrieval job from Vertica to S3 runs only once a day and this job can be re-run retroactively, the customer chose not to establish such connection. Regarding job executor and scheduler, several alternatives were discussed and Jenkins server was selected as an appropriate solution. One of the disadvantages of this approach is that this server is a single-point-of-failure. To ensure availability of the server the following measures were applied: EC2 system status checks and recovery were defined; Daily EBS volumes snapshots were defined using lifecycle management; alerts and monitoring of the server on OS and services level were defined; most of the solution was designed to use AWS native serverless components.
Performance Efficiency – Several alternatives were discussed including Jenkins, AWS Batch and CloudWatch Scheduled Events combined with AWS Lambda. Twingo architects advised to work with serverless solutions and perform decoupling of the Vertica export request (that takes significant amount of time) from further transfer to S3. Although it could improve the scalability of the solution, it would also definitely cause additional complexity. This could involve usage of SNS/SQS services. Taking this into consideration and because of customer’s previous experience, Jenkins was selected as an acceptable, trade off solution.
Security – AWS account security best practices measures were applied. CloudTrail services with a dedicated S3 bucket is created. Encryption of the REST API was achieved by encryption of all the S3 buckets involved in the solution. Lifecycle and access policies were defined to ensure that no data or relevant logs are being lost due to human error or intended harmful action. All inter-service and inter-user traffic is also encrypted using TLS. All users were defined with complex password and MFA. Several identity and access management (IAM) policies were defined according to the customer’s needs. All users are joined into appropriate groups and relevant IAM policies applied to these groups. AWS Athena Web UI access is allowed from StartApp offices only.
Cost optimizations – To ensure cost effectiveness of the solution, all data is partitioned according to business reporting needs. There are daily and monthly partitions. Partitioning of the data allows to reduce price of Athena queries. Retention policy is applied on S3 data buckets.
AWS Components
- Amazon S3
- Amazon Athena
- Amazon Glue Catalog
3rd Party components
- Apache Kafka
- Jenkins
- Spotinst





